今回の記事ではpandasについて,最低限知っておきたいことをまとめます.
Pythonでデータを扱うのに非常に便利なライブラリがpandasです.pandasを使えば簡単にファイルからデータを読み込んだり,データを処理したりすることができます.
pandasについて
外部ライブラリとなりますので,インストールが必要となります.Anacondaを使っている方はもともとインストールされているはずですので,インポートして確認してみてください.
インストールをするには...
pip install pandas
condaを使う場合:
conda install pandas
インポートは以下のようにするのが一般的です.
import pandas as pd
pandasで扱うデータ形式:DataFrame
pandasで一番よく扱うデータ形式はpandas DataFrameという2次元の配列のデータ形式です.
1次元の場合はSeries,3次元の場合はPanel(Version0.20.0以降は3次元のデータはMultiIndexを使うことが推奨されている)などありますが,今回は一番よく使うDataFrameに絞って話を進めていきたいと思います.
先ほども述べた通りDataFrameでは以下のような2次元のデータを扱っています.Excelのようなテーブルデータを思い浮かべてくれればそれが近いです.
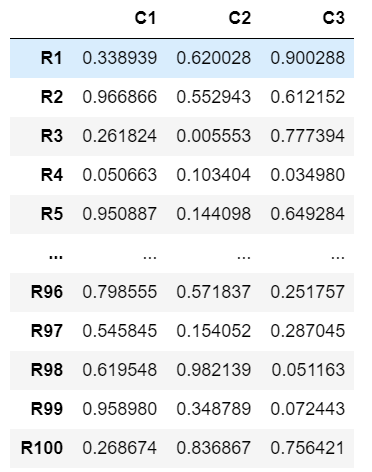
まず,pandasを使うなら覚えておかなければいけない用語を確認しましょう.
行(Row)と列(Column)の覚え方:IndexとColumns
DataFrameでデータを見るときは横向きの行(Row)と,縦向きの列(Column)として見る方法があります.
行(Row)列(Column)と縦横の関係が覚えにくい人はは以下のようにして覚えると簡単に覚えられます.
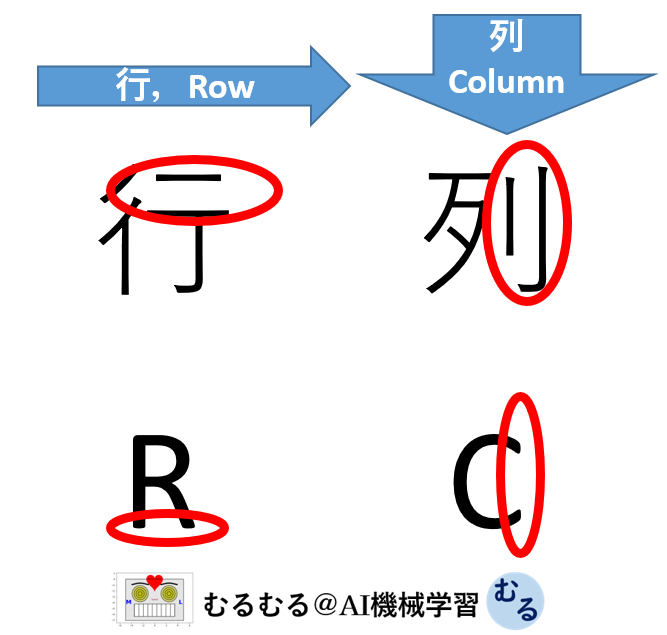
そして,DataFrameではそれぞれの行と列の名前をIndexとColumnsといいます.

無味乾燥なデータだとわかりづらいかもしれないので,以下で具体的なデータを実際にpandasを使って作ってみましょう
自分でDataFrameを作ってみる
実際にDataFrameを使うときはCSVファイルなどからデータを読み込むことが多い(後で解説)のですが,自分で作ったデータでDataFrameを作ることもできます.
pandasではDataFrame( )を使うことでDataFrameを作ることができます.以下の例を見てみましょう
# DataFrameを作る cols = ['height', 'age', 'sex'] idx = ['taro', 'hanako', 'mulumulu'] taro = [180, 20, 'male'] hanako = [160, 30, 'female'] mulumulu = [170, 28, 'male'] items = [taro, hanako, mulumulu] df = pd.DataFrame(items, index = idx, columns = cols)
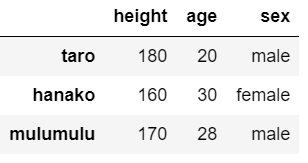
上の例では,太郎と花子とむるむるの3人のデータがDataFrameとして扱われています.
行がそれぞれ個人を表しており,列がその属性(身長,年齢,性別)を表していることがわかると思います.
DataFrameをつくるにはまずデータを用意しなくてはなりません.
上ではまずcolumnsの名前(cols = [‘height’, ‘age’, ‘sex’])とIndexの名前を(idx = [‘taro’, ‘hanako’, ‘mulumulu’])定義しています.
そのうえでそれぞれの要素(taro, hanako, mulumulu)のデータをつくりリストとしてまとめた後,pd.DataFrame()に渡しています.indexの名前とcolumnsの名前を「index = …, columns = …」とすることで,それぞれ指定することができます.
指定したIndexやColumns,または要素を抜き出す
指定したIndexやColumnsだけを抜き出すには以下のようにします.
df[columnsの名前] もしくは df[columnsの名前のリスト]
行にindexを使ってアクセス:
df.loc[indexの名前] もしくは df.loc[indexの名前のリスト]
行に番号を使ってアクセス:
df.iloc[行の番号] もしくは df.iloc[行の番号のリスト]
上で作ったDataFrameを使って練習してみましょう.
例えば,それぞれの人の年齢だけを抜き出したい場合は以下.
df['age'] ''' 出力結果:クラスがDataFrameからSeriesに変っています taro 20 hanako 30 mulumulu 28 Name: age, dtype: int64 '''
むるむると花子のデータだけ抜き出したい場合は以下.
df.loc[['mulumulu', 'hanako']]
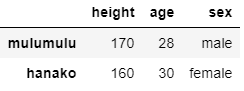
0~1番目の行データだけ抜け出したい場合は以下.
df.iloc[:2]
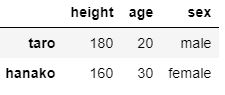
むるむるの性別にアクセスしたい場合は以下.
df.loc['mulumulu']['sex'] ''' 出力結果: 'male' '''
CSVデータの読み込みと書き込み
pandasを使えば一行でCSVファイルを読み込むことができます.「path_to_your_csvfile」のところには読み込みたいCSVファイルのPathを書いてください.
df = pd.read_csv(path_to_your_csvfile)
DataFrameからCSVデータへ書き込みたいときも一行です.
df.to_csv(path_to_your_csvfile)
CSVファイル以外にもjsonやSQLなど様々なフォーマットのデータが読み込めるので,CSVファイル以外に読み込みたいデータがある場合は調べてみてください.
DataFrameを操ろう
読み込んだデータを加工して処理したい場合もDataFrameを使えば様々なことが簡単にできます.
以下の例では先ほど使った,太郎,花子,むるむるの身長,年齢,性別のデータを使います.
特定の行・列を削除する
特定の列を削除する場合はDataFrame.drop(columns =…)とし,行の場合はcolumnsの部分をindexに変えます.
cols = ['height', 'age', 'sex'] idx = ['taro', 'hanako', 'mulumulu'] taro = [180, 20, 'male'] hanako = [160, 30, 'female'] mulumulu = [170, 28, 'male'] items = [taro, hanako, mulumulu] df = pd.DataFrame(items, index = idx, columns = cols) df2 = df.drop(columns = 'sex')
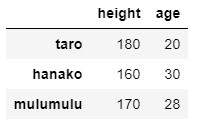
df3 = df.drop(index = 'mulumulu')
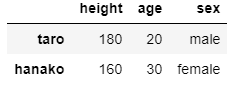
行・列を追加する
列の追加に関しては以下のようにしてできます.新しい列,’weight’を追加しています.
weights = [100, 60, 80] df['weight'] = weights
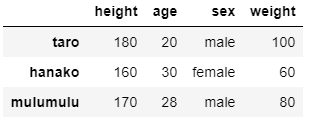
次に行を追加してみましょう.先ほど定義した「df」にJohnの情報を追加します.DataFrame.columnsとすることでDataFrameの列を取得することができます.
name = 'John' item = [[175, 39, 'male', 77]] df4 = pd.DataFrame(item, index = [name], columns = df.columns) df = df.append(df4)

上ではまず,Johnの情報だけを含んだ「df4」というDataFrameを作っています.そのうえで,もともとあった「df」に「df4」を追加するという形をとっています.indexとcolumnsはリストとして渡していることに注意してください.
条件を満たすものだけを取り出す
さて,ここからは前回追加した’John’のデータと’weight’のデータも含めたDataFrameを見ていきましょう.
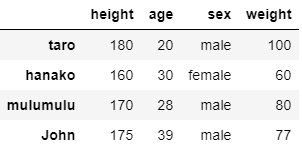
さて条件を指定するのも簡単です.例として25歳以上の人,男性,25歳以上の男性を取得してみましょう.
over25_bool = (df['age']>25) over25 = df[over25_bool]
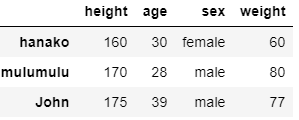
うまくいっているのがわかると思います.一行目の「over25_bool = (df[‘age’]>25)」では条件「 df[‘age’]>25) 」を満たす場合Trueそうでない場合はFalseとなるようなデータの列を取ってきています.
同様に男性だけを取り出したい場合は
guys_bool = (df['sex']=='male') guys = df[guys_bool]
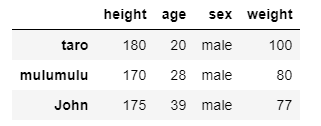
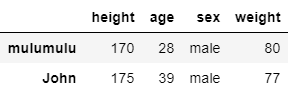
また複数の条件を指定したい場合は「&」を使って以下のようにすればよいです.
over25_guys = df[over25_bool & guys_bool]
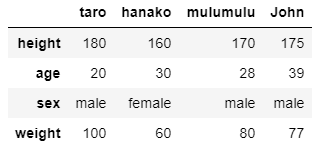
データを転置させる
DataFrame. transpose( )を使いましょう.
df.transpose()
データをソートする
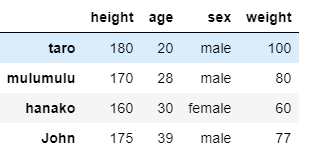
DataFrame. sort_values( )が使えます.「by = …」の部分でcolumnを指定してあげれば,そのコラムの値によってソートを行います.昇順にするか降順にするかはascendingを設定することで決めることができます.
以下では若い順にデータを並べています.
df.sort_values(by = 'age', ascending = True)
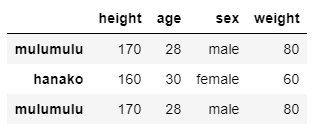
データからランダムにサンプルする
DataFrame.sample( )を使いましょう.非復元抽出/復元抽出はreplaceをFalse/Trueとすることで設定できます.
df.sample(n = 3, replace = True)
欠損値のある行・列を削除
さてデータに次のように欠損値が含まれていた場合を考えましょう.
cols = ['height', 'age', 'sex'] idx = ['taro', 'hanako', 'mulumulu'] taro = [180, None, 'male'] hanako = [160, 30, 'female'] mulumulu = [170, None, 'male'] items = [taro, hanako, mulumulu] df = pd.DataFrame(items, index = idx, columns = cols) df.head()
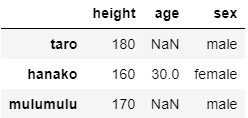
上の例では,太郎とむるむるの年齢が欠損値となっています.
欠損値の含むすべての列を削除する方法は以下.
df.dropna(axis = 'columns')

欠損値の含むすべての行を削除する方法は以下.
df.dropna(axis = 'index')

行を指定した場合と列を指定した場合で結果が違うことに気を付けてください.
行を指定した場合は,太郎とむるむるの年齢が欠損値となっているため,太郎とむるむるのデータがすべて消えてしまいます.
一方,列を指定した場合は,欠損値があるのは年齢だけなので年齢だけをDataFrameから削除することになります.
欠損値の扱いはいろいろな方法がありますが,DataFrameでは線形補完や,定数を補完する方法なども簡単にできるようになっているので興味のある人は調べてみてください.
実際にデータを分析してみよう
さて,DataFrameの基本用語やCSV読み込みについて学んだところで実際にデータを分析してみましょう.
この記事では以下のCSVファイルを使用しますが,ご自身で分析したいデータがある場合は.
path_to_your_csvfile = 'test.csv' df = pd.read_csv(path_to_your_csvfile, index_col = 'name')
以上のように「index_col = …」を指定すると,Indexに使う列を指定できます.
DataFrameの中身を一部確認したいときはhead( )を使うと上から5行だけ表示してくれます.
df.head()
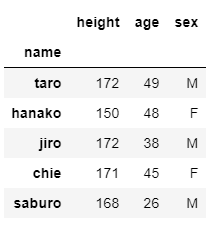
DataFrameのIndexとColumnsは以下のようにして取得できます.
cols = df.columns# columnsを取得 idx = df.index# indexを取得
記述統計量などの取得
DataFrameは便利なことに,コード一行で行ごとの平均,標準偏差,最小値や最大値などの統計量を計算してくれます.
df.describe()# 記述統計descriptive statistics
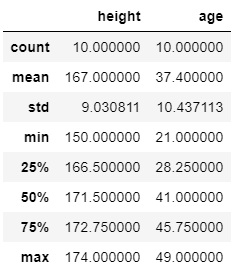
特定の統計量や特定の列の統計量だけを取得したい場合は以下のようにしてできます.
df_min = df.mean()
df_age_mean = df['age'].min()
print(df_min)
print('==========')
print(df_age_mean)
'''
出力結果:
height 167.0
age 37.4
dtype: float64
==========
21
'''
以上でpandasの基本的な操作の紹介を終わりにしたいと思います.
機械学習のためにしっかりとPythonを勉強したいなら,ある程度の基礎を身に着けた後に下の本を読むのがお勧めです.この本をこなせば,より高いレベルへ到達できるでしょう.
